Abstract
Incomplete annotation of motion information often leads to issues such as information loss and acceleration variability during pattern recognition. To address this, this study proposes a method for applying acceleration sensors in weakly-labeled motion pattern recognition. By measuring the acceleration of moving targets, an information acquisition platform and sensor network were constructed to collect kinematic data. The incomplete motion information is integrated into a weakly-labeled dataset and complemented using a semantic neighborhood learning algorithm. From the completed dataset, weakly-labeled data features are extracted, and the most relevant statistical features are selected and ranked by importance. These features are then used as input to a decision tree classifier for motion pattern recognition. Simulation results demonstrate that the proposed method achieves a recognition time of less than 3.5 seconds, a confidence level above 90%, and high recognition accuracy.
Introduction
The advancement of Internet of Things (IoT) technology, sensor technology, and smart devices has sparked growing interest in using these technological means to monitor and analyze human motion. However, the movement patterns of many target subjects—such as human walking, running, jumping, as well as robot mobility and manipulation—are often complex and highly variable. These motion patterns are difficult to accurately describe and classify using simple labels [1], making it necessary to employ more sophisticated machine learning models and methods for recognition and understanding [2]. In machine learning, data annotation is a crucial yet labor- and time-intensive process. For complex motion patterns in particular, manual labeling can be extremely challenging. In this context, accurately recognizing motion patterns has driven research on weakly-labeled motion pattern recognition as an important direction of study.
Chen et al. [3] proposed two models based on Graph Convolutional Networks (GCNs). The first model incorporates category dependencies into classifier learning via a Classifier Learning GCN (C-GCN). The second model decomposes visual representations of images into label-specific features and uses a Prediction Learning GCN (P-GCN) to encode these features. Additionally, an effective correlation matrix construction method was introduced to capture inter-class relationships, enabling multi-label image recognition.
However, this method suffers from high computational complexity, resulting in excessively long recognition times. Zhang Hongbo et al. [4] applied Principal Component Analysis (PCA) to extract the two main components of weakly-labeled motion patterns. They calculated acoustic emission signals under different motion patterns using a difference test algorithm and fed these signals into a support vector machine (SVM) for classification to achieve weakly-labeled motion pattern recognition. A limitation of this approach is that it does not impute incomplete weak labels, leading to relatively low recognition accuracy. Liu Liang et al. [5] designed six basic and five complex motion patterns. They extracted angular and displacement features based on kinematic keypoints, in addition to frequency-domain features through Fourier transform. All features were then input into a Long Short-Term Memory (LSTM) neural network model to accomplish weakly-labeled motion pattern recognition. However, this method does not prioritize highly important features, resulting in low confidence in the recognition outcomes.
To address the limitations of the aforementioned methods, this paper leverages motion data collected by acceleration sensors to generate weakly-labeled motion patterns and imputes the missing information. Subsequently, the most relevant features are selected through a feature selection process and fed into a decision tree model for weakly-labeled motion pattern recognition. By integrating these steps, the proposed approach makes full use of motion data and enhances both the accuracy and reliability of motion pattern recognition.
1 Preprocessing of Motion Information
1.1 Generation of Weakly-Labeled Sets Based on Motion Data Collected by Acceleration Sensors
Motion data acquired from sensors often contain rich information but lack specific annotations, which can lead to low accuracy in weakly-labeled motion pattern recognition. To facilitate subsequent applications in motion pattern identification, the raw data are transformed into a format suitable for machine learning algorithms. By generating a weakly-labeled set, features relevant to motion patterns can be extracted from the collected data, providing critical reference information for further motion pattern recognition.
During the movement of a target, the acceleration of all parts of its moving limbs changes continuously. Based on human kinematic characteristics, acceleration sensors are placed on specific target measurement points—such as human joints or body segments—during motion capture. By recording accelerations along different directions at these points during movement, dynamic motion information of the target is acquired. The specific procedures are as follows:
Shown in (Fig.1) is the information acquisition platform, which comprises multiple sensor nodes and is based on acceleration sensors.

Fig.1 Information collection platform based on acceleration sensor
Generally speaking, a higher sampling frequency yields more precise data but also imposes greater demands on the processor and memory. Therefore, an acceleration sensor with a 16-bit ADC (analog-to-digital converter) is selected, which can achieve a sampling rate of up to 10,000 samples per second to capture rapid movements of the target object and provide relatively accurate data. The data collected by the acceleration sensor requires processing and analysis to extract useful motion information. Using digital signal processing (DSP) methods, target motion information—primarily including limb amplitude and movement velocity—is obtained. These metrics are calculated based on the acceleration measured at limb test points, as shown in the following formula:
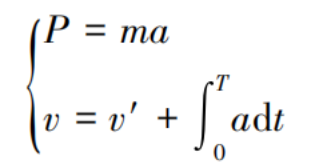
In the formula:
P represents the limb amplitude;
m denotes the mass of the target;
a indicates the acceleration;
v refers to the velocity;
v' symbolizes the initial velocity;
T stands for time;
dt represents the derivative operation.
A multi-loop network topology [6] is employed between each node controller and the main controller, using the I²C bus for communication. The I²C bus is a synchronous serial communication bus that utilizes a two-wire interface (SDA and SCL). It offers simple connectivity and supports multiple devices connected to the same bus, enabling communication between multiple node controllers and the main controller while ensuring stable and reliable data transmission. After receiving information such as limb amplitude P and motion velocity v of the target movement, the main controller transmits the corresponding data to the operator, completing the acquisition of motion information.
All motion information collectively forms the motion pattern labels. The incomplete motion information is regarded as the weakly-labeled motion pattern set D.
1.2 Weakly-Labeled Motion Pattern Imputation
For motion pattern weak labels with incomplete information, a semantic neighborhood learning algorithm [7] is employed to impute the missing data. This algorithm can fill in the gaps in a tailored manner based on the characteristics of specific samples, thereby reducing error propagation and improving prediction accuracy. The specific procedures are as follows:
Let the training set of the weakly-labeled motion pattern sample set D be denoted as K. A label output function is introduced to ensure that the output values of all samples are label vectors, thereby obtaining the label set [8], as shown in the following formula:
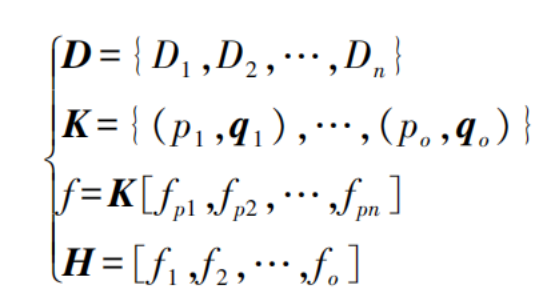
In the formula:
n represents the number of weak labels;
p denotes the motion data samples;
q indicates the label vector;
o stands for the total number of instances in the training set;
f refers to the label output function;
H represents the output label matrix.
Define an optimization objective function for the label matrix:
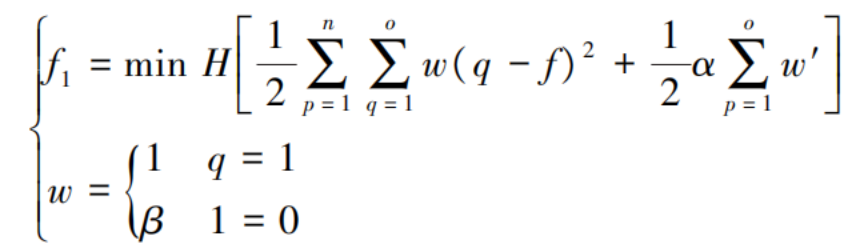
In the formula:
f₁ represents the optimization objective function;
w denotes the error weight of sample p on the label;
α indicates the regularization parameter;
w' stands for the edge weight;
β represents the neighborhood interval
The edge weights are used to construct a neighborhood graph, resulting in fixed sample distances. Under this constraint, the objective function is minimized, and the output f is smoothed over the neighborhood graph, thereby completing the imputation of missing information in the weakly-labeled motion patterns. The formula is as follows:
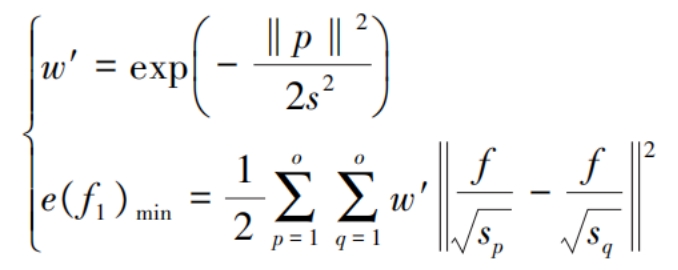
In the formula:
s represents the sample average distance;
e denotes the minimized error term.
1.3 Weak Label Feature Selection
By imputing the weak labels of motion patterns, all features are ensured to be considered during the feature selection process, thereby maximizing the retention of data information and yielding more reliable feature selection results. The Relief algorithm is capable of selecting features that carry significant information and are relevant to the target variable, thus improving the accuracy of subsequent weak label recognition. Therefore, the Relief algorithm is employed to perform feature selection on the weakly-labeled motion pattern data [9]. The specific steps are as follows:
Ranked by their importance, extract features from the imputed weakly-labeled motion pattern set. The calculation is as shown in the following formula:
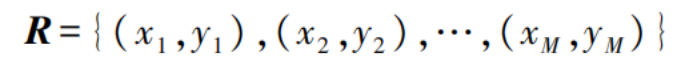
In the formula:
R represents the feature set;
x and y denote motion data features;
M indicates the number of features.
Assume that the feature set contains data from only two classes. For each feature x, define its guess-hit neighbor x₁ and guess-miss neighbor x₂. Here, the guess-hit neighbor refers to the nearest feature to x within the same-class dataset, while the guess-miss neighbor refers to the nearest feature to x within the different-class dataset. The expressions are given as follows:
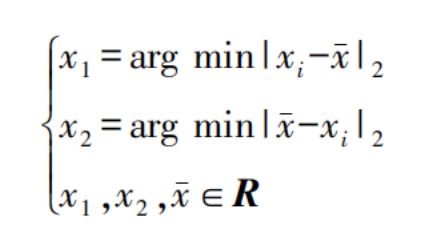
In the formula:
x̄ represents the mean value of the sample data;
i denotes the index of the i-th sample.
All data in the feature set is processed using a normalization algorithm [10], expressed as:
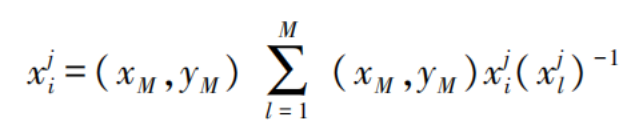
In the formula:
l represents the category;
j denotes the j-th sample.
The importance of features in the weakly-labeled motion pattern data is calculated based on order statistics [11], representing the significance level of each feature. The formula is as follows:
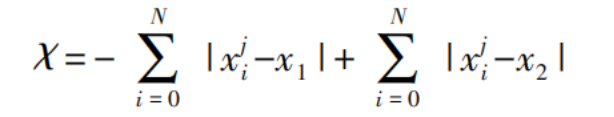
In the formula:
N represents the number of categories;
χ denotes the order statistic.
All relevant statistics of the features are arranged in descending order, and the top L feature components with the highest values are selected as the foundational data for weakly-labeled motion pattern recognition.
2 Recognition of Weakly-Labeled Motion Patterns
Based on the selected weakly-labeled motion pattern features, these features are input into a decision tree to accomplish the recognition of weakly-labeled motion patterns. As an important classification and prediction model, the decision tree [12] is implemented through the following specific steps:
A decision tree incorporating motion patterns such as static, falling, running, and jumping is constructed in a top-down recursive manner. The features are fed into the decision tree, where their attributes are compared to determine the corresponding branch paths for different properties. The structure and recognition process of the decision tree are shown in (Fig.2).
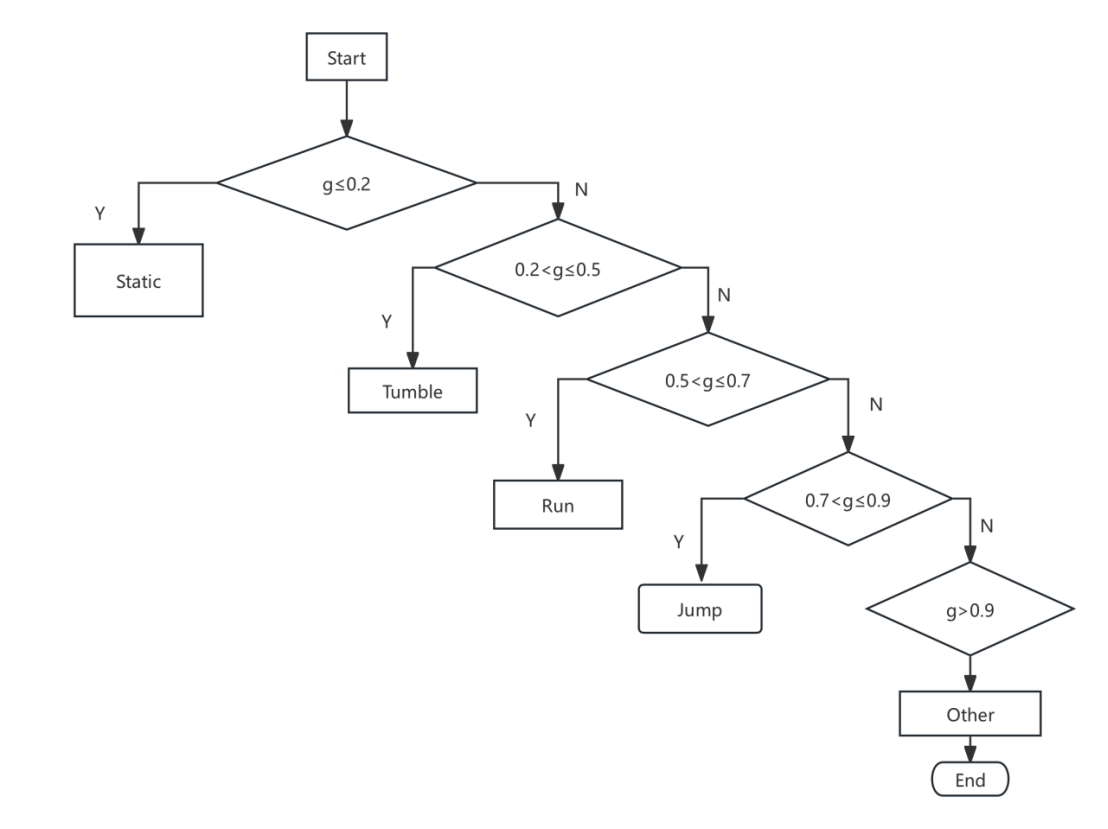
Fig.2 Motion pattern recognition structure based on decision tree
The root node of the decision tree represents the features to be classified. Information gain is used during attribute selection to measure the expected value of a feature. First, calculate the entropy of the feature sample set R:
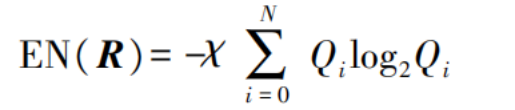
In the formula:
EN represents entropy;
Qi denotes the occurrence probability of the i-th sample.
The term entropy refers to the total amount of information that the features in R can express. Partitioned by attribute, the expected information of an attribute for R is calculated as follows [13]:
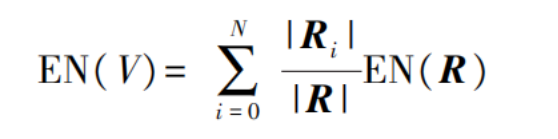
In the formula:
V represents the attribute.
By combining entropy and attributes, the information entropy [14] of the weakly-labeled motion pattern feature data is calculated as follows:
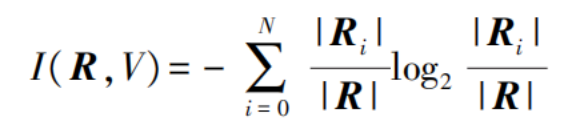
In the formula:
I represents the information entropy.
Ri denotes the i-th sample subset partitioned by the decision tree based on attribute V. The role of information entropy is to measure the uniformity of attribute splitting. Based on the information entropy, the information gain of the weakly-labeled motion pattern features is calculated as follows:
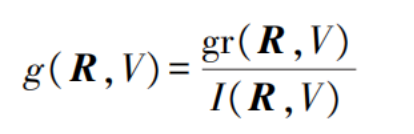
In the formula:
g represents the information gain;
gr denotes the information gain ratio.
The expected value of weakly-labeled motion pattern features is measured based on the magnitude of information gain. The recognition rules are formed by the paths from the root node to the leaf nodes in the decision tree [15].
When g ≤ 0.2, it indicates that the motion pattern of the target is static;
When 0.2 < g ≤ 0.5, it indicates that the motion pattern is falling;
When 0.5 < g ≤ 0.7, it indicates that the motion pattern is running;
When 0.7 < g ≤ 0.9, it indicates that the motion pattern is jumping;
When g > 0.9, it indicates that the motion pattern is other.
From the imputed weakly-labeled set, motion data features are extracted, and relevant statistics of these features are calculated. These features are ranked in descending order of importance, and the top-ranked features are selected as input. Using these selected features, a decision tree model is employed to accomplish motion pattern recognition.
3 Simulation Analysis
To validate the effectiveness of acceleration sensors in weakly-labeled motion pattern recognition, the following simulation experiments are conducted:
Recognition time, confidence level, and recognition accuracy are used as evaluation metrics. A comparative simulation is conducted using the proposed method, the method from Reference [3] (abbreviated as the "GCN-based method"), and the method from Reference [4] (abbreviated as the "PCA-based method"). The simulation is implemented in Python 3.9 on the Jupyter Notebook platform, and is performed on the large-scale open-source dataset UCI-DSAD for motion pattern recognition. The UCI-DSAD dataset is downloaded, and acceleration data files are read using the pandas library to generate DataFrame objects. The dataset is split into training and testing sets, with the sampling frequency of the acceleration sensor ranging from 10 Hz to 1,000 Hz.
Recognition Time
Recognition time refers to the time consumed by each method in the process of weakly-labeled motion pattern recognition. In the same simulation set, a longer recognition time indicates lower efficiency of the method, while a shorter recognition time reflects higher efficiency.
The simulation results of the proposed method, the GCN-based method, and the PCA-based method are shown in (Fig.3).
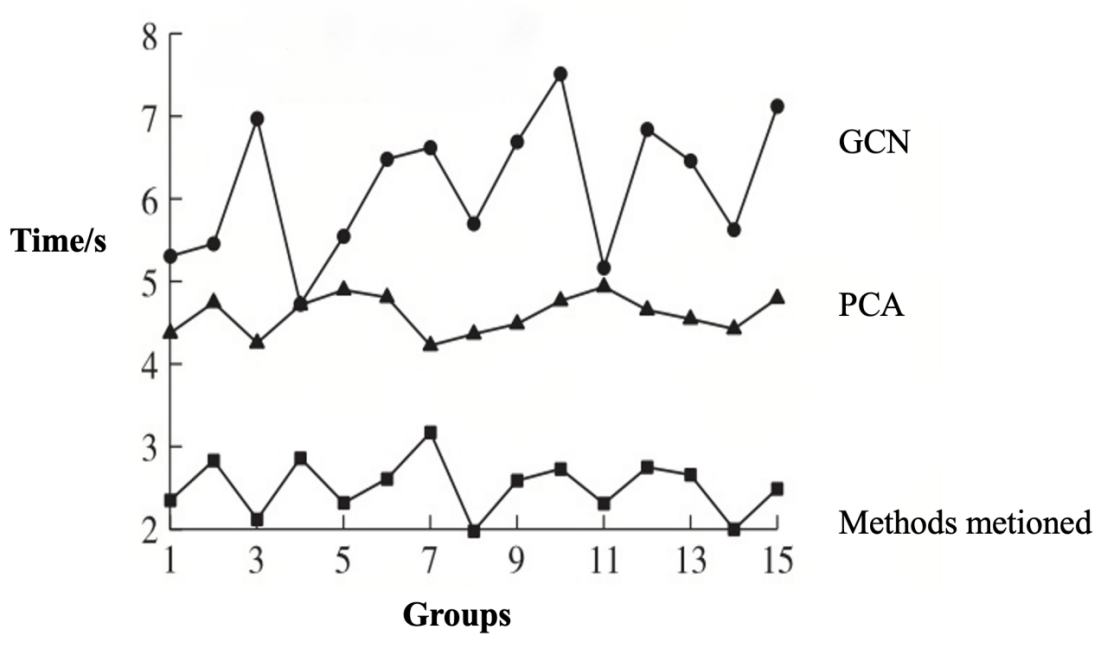
Fig.3 Recognition time of different methods
According to the data presented in (Fig.3)., the recognition time of the proposed method for weakly-labeled motion pattern recognition ranges from 1.99 s to 3.18 s. In comparison, both the GCN-based method and the PCA-based method exhibit longer recognition times than the proposed method. Under various simulation conditions, the recognition time of the proposed method is significantly shorter than that of the GCN-based and PCA-based methods, indicating higher recognition efficiency.These results demonstrate that the proposed method offers superior efficiency in handling weakly-labeled motion pattern recognition tasks. Therefore, the proposed method exhibits strong practicality and feasibility in this context. This advantage stems from its use of acceleration sensors to capture acceleration data during target movement, along with the establishment of an information acquisition platform and a sensor network. This systematic approach enables effective collection of comprehensive motion information, improving both data quality and accuracy, which in turn enhances recognition efficiency and precision.
Confidence Level
The confidence level reflects the reliability of each recognition method. The calculation formula is as follows:
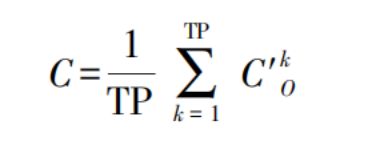
In the formula:
C represents the confidence level;
TP denotes the number of successfully recognized samples;
k indicates the motion category;
C' refers to the confidence level of true positive cases;
O represents the total number of samples.
The simulation results of the proposed method, the GCN-based method, and the PCA-based method are shown in (Fig.4).
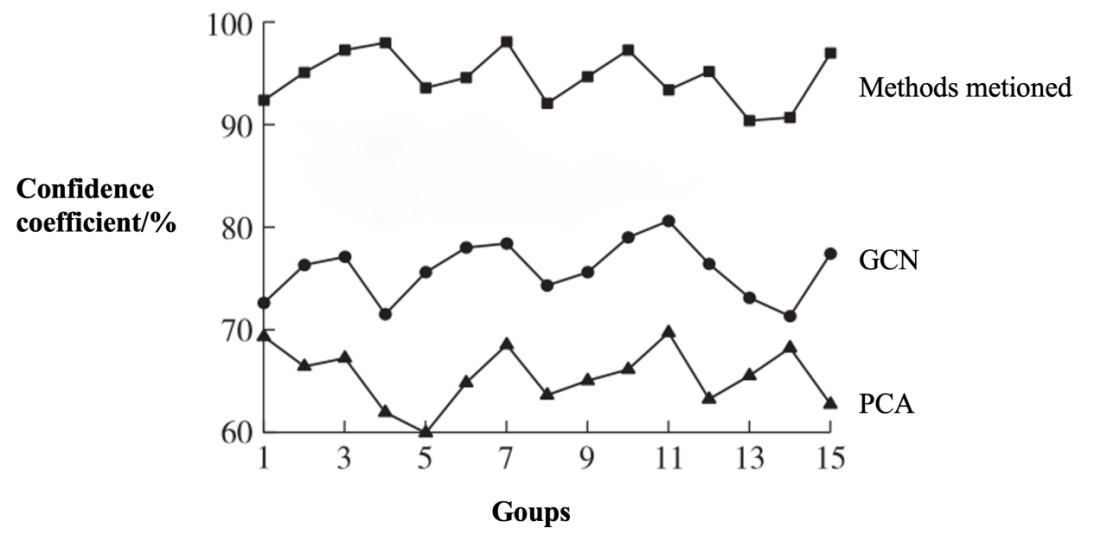
Fig.4 Confidence coefficient of different methods
Analysis of (Fig.4) shows that for weakly-labeled motion pattern recognition, the proposed method consistently achieves a higher confidence level than both the GCN-based method and the PCA-based method across all simulation groups. This indicates that the proposed method offers greater reliability in recognition compared to the other two approaches.This improvement can be attributed to the use of acceleration sensors to capture acceleration information during target motion, combined with the application of a semantic neighborhood learning algorithm during data preprocessing to impute missing weakly-labeled motion patterns. By inferring absent labels from semantically related neighboring labels, the proposed method enhances the trustworthiness of recognition.
Recognition Accuracy
In the process of weakly-labeled motion pattern recognition, the recognition results of each method are summarized. The recognition performance of different methods is shown in (Table.1).
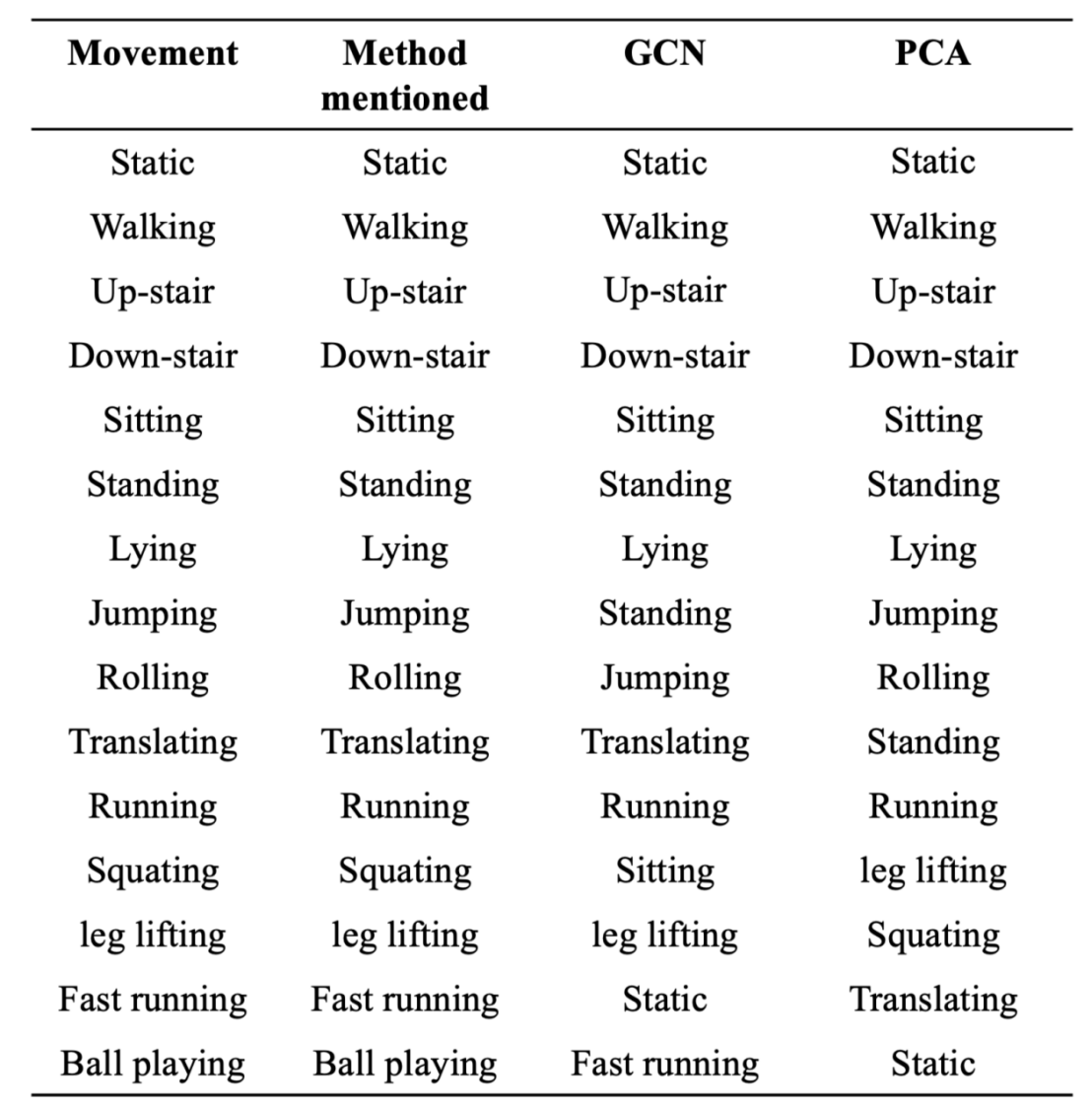
Table 1. Recognition effectiveness of different methods
Analysis of (Table.1). indicates that, in the process of weakly-labeled motion pattern recognition, the proposed method accurately identifies all motion categories. In contrast, the GCN-based method shows misclassifications in categories such as jumping, tumbling, squatting, sprinting, and ball-playing, while the PCA-based method exhibits errors in upstairs, translation, squatting, leg-lifting, sprinting, ball-playing, and other categories. These results demonstrate that the proposed method achieves higher recognition accuracy than both the GCN-based and PCA-based methods.This improvement is attributed to the fact that the proposed method incorporates imputation of incomplete weak labels during the recognition process and employs a decision tree as the classifier for motion pattern identification. Decision trees offer advantages such as ease of interpretation and implementation, enabling effective judgment and classification of diverse feature combinations. The use of a decision tree allows the model to flexibly adapt to various motion pattern scenarios, thereby further enhancing recognition accuracy.
Discussion
Current methods for weakly-labeled motion pattern recognition suffer from issues such as long recognition time, low confidence, and low accuracy. To address these challenges, this study proposes an application of acceleration sensors for weakly-labeled motion pattern recognition. The method leverages acceleration sensors to acquire dynamic motion information of the target, employs a semantic neighborhood learning algorithm to impute missing weak labels, and utilizes the Relief algorithm to select discriminative features from the motion data. These features are then fed into a decision tree model to accomplish weakly-labeled motion pattern recognition. Simulation results demonstrate that the proposed method achieves a recognition time within 3.5 seconds, a confidence level exceeding 90%, and high recognition accuracy. This indicates that the method can efficiently recognize motion patterns with highly reliable results, demonstrating significant potential for dynamic state monitoring and behavior recognition of targets.
References
[1] Bila H, Paloja K, Caroprese V, et al. Multivalent Pattern Recognition through Control of Nano-Spacing in Low-Valency Super-Selective Materials[J]. Journal of the American Chemical Society, 2022, 144(47): 21576-21586.
[2] Lai X Y, Chen S, Yan Y, et al. A Survey of Deep Learning-Based Facial Attribute Recognition Methods[J]. Journal of Computer Research and Development, 2021, 58(12): 2760-2782.
[3] Chen Z M, Wei X S, Wang P, et al. Learning Graph Convolutional Networks for Multi-Label Recognition and Applications[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45(6): 6969-6983.
[4] Zhang H B, Pang Y Q, Li X T, et al. Statistical Analysis and Pattern Recognition of Knee Joint Acoustic Emission Signals[J]. Journal of Electronic Measurement and Instrumentation, 2021, 35(8): 198-204.
[5] Liu L, Pu H Y. Real-Time Recognition of Multi-Dimensional Feature Gestures Based on LSTM[J]. Computer Science, 2021, 48(8): 328-333.
[6] Jing X, Zhou Z T, Wang Y L. An Improved Routing Algorithm for Complex Multi-Loop Network Topologies[J]. Computer Engineering, 2022, 48(3): 154-161.
[7] Yao Z J, Zhao C H, Li Y L, et al. A Customized Generative Adversarial Data Imputation Model for Industrial Soft Sensing Applications[J]. Control and Decision, 2021, 36(12): 2929-2936.
[8] Wang J, Xu W, Ding Y, et al. Multi-Label Text Classification Based on Graph Embedding and Regional Attention[J]. Journal of Jiangsu University (Natural Science Edition), 2022, 43(3): 310-318.
[9] Kundu R, Singh P K, Chattopadhyay S, et al. Pneumonia Detection from Lung X-Ray Images Using Local Search Aided Sine Cosine Algorithm Based Deep Feature Selection Method[J]. International Journal of Intelligent Systems, 2022, 37(7): 3777-3814.
[10] Zhang H, Mi B, Liu Y, et al. A Pitfall of Applying One-Bit Normalization in Passive Surface-Wave Imaging from Ultra-Short Roadside Noise[J]. Journal of Applied Geophysics, 2021, 187: 104285.
[11] Gong K L, Zhai T T, Tang H C. An Online Active Learning Algorithm for Multi-Label Classification[J]. Journal of Shandong University (Engineering Science), 2022, 52(2): 80-88.
[12] Zheng Z, Zou J Y. Research on Motion Data Classification Based on Chaotic Correlation Dimension and Decision Tree[J]. Computer Simulation, 2022, 39(10): 327-330, 424.
[13] Fang W, Wang Z, Giles M B, et al. Multilevel and Quasi Monte Carlo Methods for the Calculation of the Expected Value of Partial Perfect Information[J]. Medical Decision Making, 2022, 42(2): 168-181.
[14] Zhang F H, Liu L, Zhu J D, et al. Research on Data Adaptive Clustering Based on Information Entropy Weight Update[J]. Electronic Design Engineering, 2023, 31(16): 176-179, 186.
[15] Wei Y, Lai J X, Zhou Q L, et al. Exploration of Recognition Rules and Processing Methods for Abnormal Data in Automatic Monitoring of Pollution Sources[J]. Environmental Monitoring Management and Technology, 2022, 34(2): 56-59.